Sample-efficient learning
...using global optimization

We explore how to reduce sample complexity in data-driven policy learning through global optimization tools.
Policy learning from data is one of the fundamental capabilities to create intelligent robots at scale, but predominant methodologies are highly sample-inefficient, requiring hundreds of hours of interactions with a simulator or real hardware to teach a robot even basics skills. When robot morphology, task descriptions, or the environment change, the policy often have to be retrained or finetuned / recalibrated.
We explore research directions that reduce the sample complexity, the amonut of interactions or data points required, for robot learning. Past research has included the following.
1. Surrogate-based learning
We explore how to use surrogate methods that map control actions to expected rewards, using those models to steer the robot towards optimal solutions. Crucially, when we choose surrogate models with global optimization in mind, we can choose models that are both accurate and usable by global solvers. We show this by adopting KernelSOS to optimal control and estimation problems.
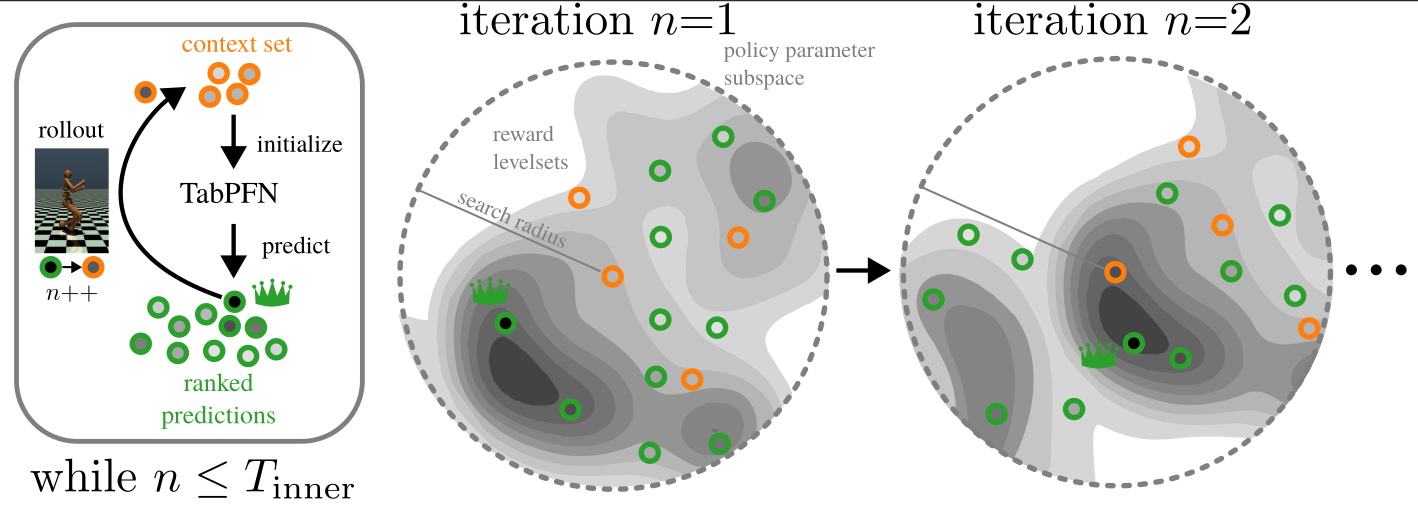
2. Tabular foundation models
In surrogate-based learning, significant manual work and domain expertise is often required to construct effective model classes. The chosen models are usually application-specific and the work as to be repeated when requirements change. We explore how to use foundation models – predictors that have been trained on vast corpori of heterogeneous data – as surrogate models that can be efficiently constructed as new data is coming in. For example, we show that tabular foundation models can increase sample efficiency in policy learning, where they can be used as surrogates for reward predictions for different policy parametereizations.
3. Innovative model learning
Finally, in past work we have turned to Koopman-inspired methods for sample-efficient learning. Originally, these methods were used to find a linear representation of system dynamics. When combined with methods that also learn a linear representation of measurement models, we can use good-old Kalman filtering and LQR control to create an end-to-end optimal estimation and control loop that is both sample-efficient and globally optimal.
A common thread of the above works is that we effectively close the loop between modeling and optimization. We dive deeper into this topic in Optimal problem formulation.